Spam Mail Detection System using Logistic Regression
1. Introduction :
Email spam, also called junk email, is unsolicited messages sent in bulk by email (spamming). The name comes from Spam luncheon meat by way of a Monty Python sketch in which Spam is ubiquitous, unavoidable, and repetitive.
In this article I will show you how to create your very own program to detect email spam using a Machine Learning technique called Logistic Regression.
Before we start talking about the algorithm and the code, take a step back and try relating that simple explanation of spam detection with monthly active Gmail account(which is approximately 1 billion). Lets take a look over steps of my experimentation.
2. Steps of my Experimentation :
- Data Acquisition and Data Pre-Processing : I have took dataset from kaggle. It has tagged email that have been collected for Spam research. It contains one set of messages in English of 5,574 emails, tagged according being legitimate(ham) or spam.
- Applying Machine Learning Algorithms : Logistic Regression measures the relationship between the categorical dependent variable and one or more independent variables by estimating probabilities using a logistic function. From the definition it seems, the logistic function plays an important role in classification here but we need to understand what is logistic function and how does it help in estimating the probability of being in a class.
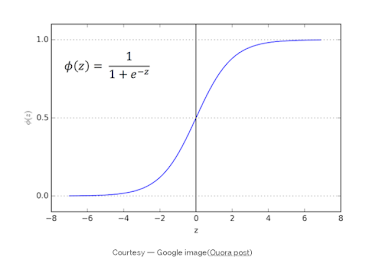
Fig 1.
The formula mentioned in the above image is known as Logistic function or Sigmoid function and the curve called Sigmoid curve. The Sigmoid function gives an S shaped curve. The output of Sigmoid function tends towards 1 as z → ∞ and tends towards 0 as z → −∞. Hence Sigmoid/logistic function produces the value of dependent variable which will always lie between [0,1] i.e the probability of being in a class.
- Feature Extraction : Feature extraction is a process of dimensionality reduction by which an initial set of raw data is reduced to more manageable groups for processing. A characteristic of these large data sets is a large number of variables that require a lot of computing resources to process. Feature extraction is the name for methods that select and /or combine variables into features, effectively reducing the amount of data that must be processed, while still accurately and completely describing the original data set.
- Result and Analysis of ML : I have built a spam mail predictive system with the accuracy of 96.59 %. So, its a quite good accuracy for a system.
 Fig 2.
Fig 2.
3. Conclusion :
As we saw, we used previously collected data in order to train the model and predicted the category for new incoming emails. This indicate the importance of tagging the data in right way. One mistake can make your machine dumb, e.g In your gmail or any other email account when you get the emails and you think it is a spam but you choose to ignore, may be next time when you see that email, you should report that as a spam. This process can help a lot of other people who are receiving the same kind of email but not aware of what spam is. Sometimes wrong spam tag can move a genuine email to spam folder too. So, you have to be careful before you tag an email as a spam or not spam.
Comments
Post a Comment